Le défi initial
Une entreprise industrielle avait confié à un data scientist junior la mission de développer un chatbot basé sur du RAG pour répondre aux questions réglementaires internes.
Malgré une première version fonctionnelle, le prototype présentait des lacunes importantes : absence d’évaluation automatique, structure de code peu industrialisable, et performances limitées sur des formats complexes comme les tableaux et images.
De plus, le code était essentiellement créer sur des environnements Jupyter Notebooks qui ne permettent pas de rendre exploitable le chatbot au grand public.
Le contexte était d’autant plus exigeant que le domaine nécessite une fiabilité absolue : les réponses doivent croiser plusieurs sources réglementaires et éviter toute hallucination.
Notre approche en 3 étapes
Étape 1 : Audit de l’existant
Nous avons analysé en profondeur la solution développée pour identifier les forces et les axes d’amélioration. Le diagnostic a révélé un bon niveau technique de l’équipe et une connaissance des concepts de RAG, mais une absence de méthodologie pour passer en production.
Étape 2 : Formation du data scientist
Une formation intensive de 2 jours a permis de transmettre les bonnes pratiques essentielles :
- Structuration d’un projet RAG modulaire et maintenable
- Méthodes d’évaluation avec des KPI métiers et techniques
- Techniques avancées (re-ranking, prompt engineering, gestion de formats mixtes)
- Principes de déploiement et de CI/CD
Étape 3 : Mentorat hebdomadaire
Pendant 3 mois, nous avons accompagné l’équipe avec des sessions de suivi régulières, des revues de code, et un accès direct à notre expert Rémy. Le comité de projet était impliqué pour garantir l’alignement avec les objectifs métiers.
L’accompagnement était structuré avec un plan d’implémentation par sprints :
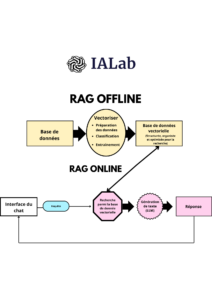
- Semaines 1-2 : Refonte de l’architecture (notebooks → projet Python modulaire)
- Semaine 3 : Pipeline RAG fonctionnel avec fonction
ask_question()en CLI
- Semaine 3 : Pipeline RAG fonctionnel avec fonction
- Semaine 4 : Interface Streamlit
- Semaines 5-6 : Évaluation automatique et définition des KPI métiers
- Semaines 7-8 : Tests de modèles, embeddings et prompts de reformulation
- Semaines 9-10 : Intégration de re-rankers et enrichissement par métadonnées
- Semaines 11-14 : Tests, packaging et documentation complète sur Confluence
Les défis rencontrés et surmontés
Le défi de l’évaluation métier
La plus grande difficulté n’était pas technique mais organisationnelle : constituer une équipe d’experts métiers pour valider les réponses. Contrairement aux métriques classiques de ML (précision, recall), évaluer un RAG nécessite des experts capables de juger la complétude et la véracité des réponses.
Solution mise en place : Développement d’une évaluation automatique en parallèle, permettant au data scientist de tester de nombreuses hypothèses avant sollicitation des experts. Focus sur la détection des faux positifs et la qualité des chunks récupérés.
Le défi de la souveraineté
Exigence forte : tout devait rester 100% en local. De l’utilisation initiale de GPT, nous sommes passés à des modèles open-source (Mistral 7B, Qwen 14B) déployés sur GPU interne.
Le défi de la fiabilité
Dans le domaine réglementaire, citer ses sources et éviter les hallucinations sont critiques. Le système développé affiche systématiquement les chunks utilisés avec leurs scores de pertinence, permettant aux experts de valider la traçabilité des réponses.
Résultats obtenus
À l’issue de ces 3 mois, l’entreprise dispose désormais d’un outil opérationnel :
- Un pipeline RAG structuré et maintenable avec déploiement automatique
- Une interface utilisateur fonctionnelle permettant la collecte de feedbacks
- Des métriques d’évaluation pour mesurer et améliorer les performances
- Une documentation complète pour faciliter les évolutions futures
Les premiers retours utilisateurs sont exploitables et permettent déjà d’orienter les améliorations.
Et maintenant ?
L’accompagnement se poursuit avec une approche d’amélioration continue :
- Tests d’hypothèses hebdomadaires avec mesure des performances
- Exploration de techniques avancées (RAG agentique, graphs de connaissance)
- Extension du pipeline à d’autres domaines métiers de l’entreprise
L’objectif n’est pas la perfection, mais un outil d’aide à la décision fiable qui fait gagner du temps aux experts tout en garantissant la traçabilité des informations réglementaires.
Vous souhaitez industrialiser vos projets IA ? IALab accompagne les entreprises dans le passage de l’expérimentation à la production avec une approche pragmatique « Done with you » ou « Done for you ». Dans les deux cas : formation, mentorat technique et suivi régulier pour garantir la montée en compétences de vos équipes.