Qu'est-ce que le RAG ?
Le Retrieval-Augmented Generation (RAG) est une technique d’intelligence artificielle qui combine les capacités de récupération d’information (retrieval) et de génération de texte (generation).
Le RAG est un système qui permet aux chatbots et agents conversationnels de communiquer en s’appuyant sur une base de connaissances. Il désigne le mécanisme d’extraction des données dans une base puis de génération de texte à partir de ces données.
Fonctionnement du RAG
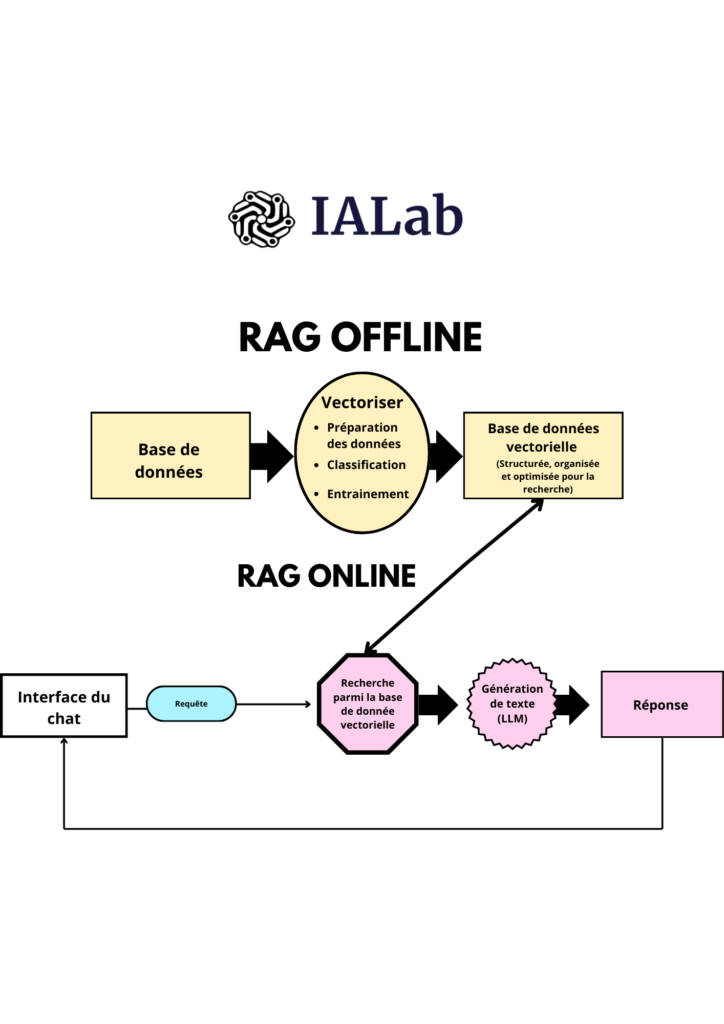
La partie offline
La partie offline du RAG est le processus préliminaire où le système organise et prépare sa base de données de connaissances, qui sera utilisée pour améliorer la génération de réponses pertinentes et informées lors des interactions en temps réel.
Elle comporte 4 étapes:
Préparation des données: Dans la phase offline, le modèle RAG commence par constituer une base de données de documents ou de passages textuels. Ces données peuvent provenir de diverses sources telles que des articles, des livres ou des sites web.
Indexation: Après avoir rassemblé les données, elles sont indexées pour permettre une recherche rapide et efficace. Cette indexation est similaire à celle utilisée par les moteurs de recherche pour cataloguer les pages web.
Intégration du modèle de récupération: Le modèle de récupération est configuré pour interroger l’index et récupérer les documents les plus pertinents en fonction d’une question ou d’une requête donnée. Cela est généralement réalisé à l’aide d’algorithmes de correspondance de texte ou de similarité sémantique.
Entraînement du modèle: En mode offline, le modèle est également entraîné pour apprendre à générer des réponses en utilisant les informations extraites des documents récupérés. Cela implique l’apprentissage de la manière d’intégrer les données récupérées pour améliorer la qualité et la précision des réponses générées.
La partie online
La partie « online » du modèle RAG en intelligence artificielle consiste en l’exploitation en temps réel des informations préparées durant la phase offline pour générer des réponses aux questions posées par les utilisateurs.
Requête utilisateur :
- Analyse de la requête : Lorsqu’une question est posée, le modèle analyse le texte pour comprendre le sujet et identifier les mots clés essentiels. Cette analyse peut inclure l’extraction de termes spécifiques, la reconnaissance des entités nommées (noms de personnes, lieux, etc.), et la compréhension de la structure grammaticale pour déterminer l’intention de la question.
- Formulation de la requête de recherche : À partir des mots clés et des concepts clés identifiés, le modèle formule une requête qui sera utilisée pour interroger la base de données documentaire. Cette requête est optimisée pour maximiser la pertinence des documents retrouvés.
Récupération des documents :
Recherche dans la base de données : Le modèle utilise la requête formulée pour effectuer une recherche dans sa base de données. L’efficacité de cette recherche dépend de la qualité de l’indexation et de la précision de la requête.
Sélection des documents : Les documents sont sélectionnés en fonction de leur pertinence par rapport à la requête.
Cette pertinence est souvent évaluée à l’aide de métriques telles que le score TF-IDF (fréquence du terme-inverse de la fréquence des documents) ou des techniques plus avancées comme le BERT (modèles basés sur les transformers) pour la compréhension contextuelle.
Génération de la réponse :
- Extraction d’informations : Une fois les documents pertinents récupérés, le modèle extrait les passages les plus informatifs. Cette étape peut impliquer un résumé des informations ou une sélection de snippets (extraits textuels) qui répondent directement à la question posée.
- Synthèse de la réponse : Le modèle intègre ensuite les informations extraites pour générer une réponse cohérente. Cette synthèse peut être enrichie par des techniques de génération de langue naturelle pour assurer que la réponse soit non seulement informative mais aussi fluide et naturelle.
Exemple Concret
Pour un assistant virtuel dans une entreprise, le processus se déroule comme suit :
- Demande Utilisateur : L’utilisateur pose une question spécifique.
- Recherche : Le module de récupération extrait les documents pertinents de la base de connaissances de l’entreprise.
- Génération de Réponse : Le modèle de génération formule une réponse en intégrant les informations extraites.
Les cas d’usage du RAG
Support client
Le RAG permet de fournir des réponses personnalisées et précises aux clients en accédant en temps réel à une base de données exhaustive de l’entreprise.
Cela améliore l’expérience client en offrant des solutions adaptées à chaque requête spécifique.
Génération de contenu
Dans le marketing, le RAG est utilisé pour créer des articles, des billets de blog et des descriptions de produits personnalisés pour le public cible, en s’appuyant sur des données de recherche pertinentes. Cela rend le contenu plus engageant et pertinent.
Ventes
Le RAG dynamise les stratégies de vente en créant des propositions commerciales sur mesure, en analysant les interactions précédentes avec les clients pour générer des scripts de vente optimisés et des points de discussion pertinents.
Éducation et apprentissage en ligne
Dans le tutorat virtuel, le RAG peut répondre aux questions spécifiques des étudiants en récupérant des informations pertinentes, offrant ainsi des réponses bien informées et personnalisées qui améliorent l’expérience d’apprentissage.
Diagnostic des soins de santé
Le RAG révolutionne le diagnostic médical en récupérant automatiquement les dossiers médicaux pertinents et en générant des diagnostics précis et complets, ce qui permet de gagner du temps et d’offrir des soins plus personnalisés.
Les limites du RAG
Le RAG (Récupération-Augmentation-Génération) présente plusieurs défis importants malgré ses nombreux avantages. La qualité et la pertinence des informations générées par ce système dépendent fortement de la qualité du corpus de documents sous-jacent.
Si les données disponibles sont incomplètes ou biaisées, les réponses produites seront également affectées. De plus, l’intégration efficace des informations récupérées dans la génération de texte reste un défi technique majeur, nécessitant des algorithmes sophistiqués pour assurer une cohérence et une fluidité optimale.
Enfin, des considérations éthiques et de confidentialité sont cruciales, car il est impératif de veiller à ce que les informations utilisées respectent la vie privée des individus et les réglementations en vigueur.
Ces défis doivent être surmontés pour que le RAG puisse atteindre son plein potentiel de manière fiable et éthique.
Comment IALab utilise le RAG dans ses solutions IA ?
Nous utilisons le Retrieval-Augmented Generation (RAG) pour renforcer la précision et la pertinence de ses solutions IA dans divers domaines.
Par exemple, dans les chatbots et assistants virtuels, le RAG permet de récupérer des informations spécifiques à partir de vastes bases de données, garantissant des réponses précises et contextualisées aux utilisateurs.
Nous utilisons aussi le RAG dans le domaine de l’analyse de données.
Cela nous permet d’extraire et synthétiser des informations à partir de grands ensembles de données, permettant la création de rapports détaillés et la prise de décisions basée sur des données actualisées.
L’utilisation de cette technologie est particulièrement utile dans les secteurs où les données évoluent rapidement, comme les marchés financiers ou les tendances de consommation.



